Information management notes
| Type classification: this is a notes resource. |
| Completion status: Almost complete, but you can help make it more thorough. |
Introduction
editThis page serves as a place to collect thoughts (and resources) on the topic of managing information for the purposes of:
- accessibility
- reuse/repurposing
- archiving
- increasing user acceptance/adoption (data capture stage as well as data use)
The objective of collecting these thoughts is to organize a rationale for how to use the various available tools on a collaborative scientific project which is expected to generate information products of lasting value. In the near term, a specific project will be driving the development of this solution. However, it is hoped that the salient features of both the problem and the solution can be distilled into a more generalized understanding which will aid projects of this type.
Theme
editFor the purposes of this effort, modern information systems are defined as being comprised of both human and machine. Humans are involved at the start, and are ultimately the audience for any information. It is ultimately the human's job to understand the information asset in order to effectively discharge their roles as producers and consumers of information. Between the producers and consumers are the custodians, which are often machines.

In the above figure, the rectangles represent individuals involved with the understanding of the material. The circle represents the storage system, which is capable of storing, preserving, indexing and retrieving the material without attempting to understand it.
Information management, in the context of this producer-custodian-consumer model, involves defining the responsibilities and expectations of each role as well as how the roles interact.
Custodian Role
edit- Custodians of information do not need to understand the information in the item itself.
- Custodians must keep items safe from destruction and alteration
- Custodians must be able to accept new items and retrieve them later.
- Custodians must be able to index items, for example:
- Traditional "card catalog" found in libraries:
- by subject
- by author
- by title
- by "groups" of holdings
- by characteristic properties
- Traditional "card catalog" found in libraries:
Producer Role
edit- Producers provide information resources to the custodian.
- Producers typically understand the information.
- Producers determine what constitutes a "group" of documents.
- Producers define what (if any) additional characteristic properties apply to the group.
- Producers determine values for each of the characteristic properties for each information resource provided to the custodian.
Author subrole
edit- The producer created the item submitted to the custodian
- Accepts queries about the contents of this item
- Producers respond to consumer requests for explanatory or additional information about an information resource.
Translator subrole
edit- Producer acquired the item from some other source and submitted it to the custodian
- Producer includes lineage information to indicate the origin of the document.
Consumer Role
edit- Consumers are qualified to learn the information in the resource.
- Consumers search for information resources and groups of information resources held by the custodian, using the defined properties.
- Consumers request information resource holdings from the Custodian.
- Consumers probably want to subset the information holdings in unanticipated ways.
- Consumers direct requests for explanatory or additional information to the producers.
Collections of holdings
edit- May be ad-hoc or systematized.
- Ways to define membership in a collection:
- Declarative (by explicitly claiming membership)
- Implicit/type (by possessing properties characteristic of all members in the collection)
- Implicit/instance (by possessing property values characteristic of all members in the collection)
- Systematized collection schemes may include the notion of superior and subordinate grouping levels, as in a hierarchy.
- Implicit schemes, depend on each item advertising its own intrinsic characteristics
- this is more extensible
- this is easier to validate
- Declarative schemes depend on each item asserting that they belong to a collection.
- this includes no information as to why the item is part of the group
- thus it is harder to later group items in unanticipated ways.
Hierarchical Classification
edit- Special case:
- all leaves are the same distance from the root
- all nodes which are the same distance from the root are the same "type"
- Two methods to implement hierarchical classification:
- tree of nodes
- common set of properties
- Differences in searching/forming groups:
- locating subtrees
- searching for a value (or combination of values) in the correct property(ies)
- Typically in a hierarchical classification tree, each level (in "distance from the root of the system") has a specific meaning, and would always map to the same property. See the following.
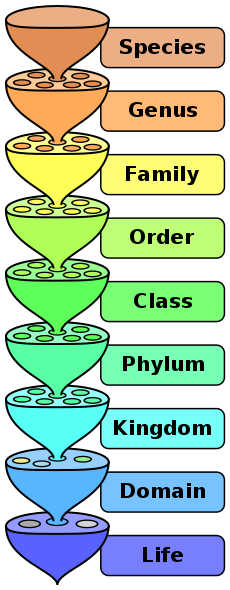

If the above were:
- implemented as a "tree",
- a set of categories would be created to reflect the accepted "Domains", "Kingdoms", "Phylums"
- Each category/subgroup explicitly claims membership in the appropriate superior node.
- Each resource explicitly claims membership in the appropriate category in the tree.
- Resources which participate in this classification scheme are identified because they claim membership in something which can trace it's lineage back to the root node of the scheme...in this case, "life".
- implemented as a set of properties,
- resources which participate in the classification scheme are identified by the presence of properties without regard for their value. The presence of subordinate properties is optional, but if one of the properties is set, all superior properties must also be set.
- resources are located within the classification scheme by the values stored in the relevant properties.
- the hierarchy can be derived by selecting all participants in the scheme and analyzing the property values.
- An explicit category structure is not required.
Collection membership as a managed entity
editConsistency is expected from members of the same collection. There are three levels of consistency:
- the manner or system in which properties get their values and/or membership is asserted
- the presence of properties
- the meaning of property values
Automated extraction of information related to characteristic properties is a requirement for large holdings of information resources, and this requires a consistent, deterministic expression. Relying on a human reader to interpret information on a case by case basis is simple to set up but requires a high level of tedious and error-prone effort to maintain. Additionally, the properties which are only accessible to a human reader are not available for searching and filtering.
The criteria for collection membership must be consistently applied to all members of the collection. If criteria are to change or the collections are to evolve, the collection system itself should be versioned, and each member must be updated such that it is consistent with the new definition.
Example: setting property values
editConsider the "collection" of reports in the US Forest Service Fire Effects Information System (FEIS). In the article describing Abies fraseri, the states in which Abies fraseri exists are coded as follows:
<b>STATES : </b>
NC TN VA
In the same collection, the report describing the effects of fire on Anas acuta presents the states in which the bird lives as:
<b>STATES : </b>
<table cellspacing="5" cellpadding="5" border="0">
<tr>
<td>AL</td>
<td>AK</td>
<td>AZ</td>
<td>AR</td>
<td>CA</td>
<td>CO</td>
<td>CT</td>
<td>DE</td>
<td>FL</td>
<td>GA</td>
</tr>
...
</table>
In the first case, a whitespace separated list is used and in the second case, HTML table markup is used. Other inconsistencies include the designation of the name of the property to which values are being assigned: sometimes a boldface string is used, sometimes a third-level heading is used. The boldfaced string is especially problematic for automatic processing because it is not guaranteed that all bold text signifies a property name. It is only that the bold text is on its own line with a colon after it which causes the human reader to infer that a list of states follows. Likewise, the human will immediately recognize that the states form a "list" and the table markup is merely a device to make the list more compact. There is no significance to states being in the same row or the same column.
In the situation where a human consumer is intended to interpret and process the information, authors are free to use any expression which effectively communicates to the human. When the intent is to supply information to a computer, authors must effectively communicate meaning to the computer. Once the computer understands the content, it can present the information to the human in a variety of ways.
Example: Controlling property values
editIdeally, there is a one-to-one relationship between a concept and the property value which represents that concept. This ensures that the Producers who supply property values are following the same rules used by the Consumers who construct searches. Falling short of this ideal leads to the situation where producers could tag an article with the string "CO2", and Consumers search for "carbon dioxide". The Custodian will not return the desired information resources because Producers and Consumers used alternate means of expressing the same thing.
To solve this problem in the field of chemistry, the International Union of Pure and Applied Chemistry (IUPAC) has made an attempt to standardize the means of referring to chemical substances and compounds. This standard method is called the International Chemical Identifier (InChI). The fixed length equivalent of this identifier, InChIKey, looks much like a random string of characters. Both identifiers may be automatically generated from a description of the molecular structure itself. In addition, there is a human readable standard name. One public database of many chemical compounds and substances is Pubchem.
For the purposes of having the Producers and Consumers follow the same rules, it is clear that an algorithm which deterministically generates a text representation of a chemical given the structural information is preferable to a human readable name. Human nomenclature tends to evolve over time, and alternate names are often widely recognized by practitioners. Successfully searching by a chemical name may depend on knowing the person who entered the information into the collection of holdings, or knowing when it was entered.
Identification of chemical substances to humans and the computer may require "related properties." These properties should be synchronized to all refer to the same item or concept. In this example:
| Property Name | Allowed Values | Example |
| IUPAC_Name | Official name of the chemical | carbon dioxide |
| InChI | String generated by the InChI algorithm | InChI=1S/CO2/c2-1-3 |
| InChIKey | String generated by fixed length InChI algorithm | CURLTUGMZLYLDI-UHFFFAOYSA-N |
| InChIVersion | Version of InChI algorithm used to generate identifiers. | 1.02 |
Example: Explicitly defining allowed property values
editFor the case where the number of allowable property values is manageably small, it is possible to enumerate the identifiers. Enumeration effectively controls the representation of a unique concept to the computer, but it does not communicate the concept itself to the human. For instance, setting the "Instrument" property to the value "1" effectively distinguishes instrument number one from all the other instruments. However, it does nothing to communicate anything about that instrument: what does it measure; what is the make, model, serial number of the instrument, when was its most recent calibration?
For each property, it is important to define the list of permissible meanings and the list of permissible representations for those meanings. The representation must be machine readable and distinct from all other representations of the same type. The meaning may be automatically comprehensible (as in a table) or written for human consumption (as in prose).
Defining instances of a type for subsequent reference
editThere are times when it is insufficient to simply define an enumeration of values. At times it is necessary to provide a more complete description about what the enumeration refers to. This strategy collects the descriptive information into one place and allows other managed objects simply to refer to it. When the reference is used as the value of a property, specific meaning can be conveyed: i.e., an "instruments used" property could refer to another object within the system; an "analytes" property could contain a link to a substance description on pubchem. In both cases, the target of the reference explains the meaning of the property value.
When it is necessary to describe specific instances, it is probable that a common "type" has already been defined. Similar if not identical information will be provided about each instance of the type. In the case of an "Instrument", a good, common set of properties might be: "Manufacturer", "Model", "Serial Number", "Last calibration date". It could also be that each instrument has additional/unique information which can be filled out, or which is not machine-interpretable.
There are two options for defining instances of a common type:
- If the type is completely machine-comprehensible, the instances could be defined in a single table.
- For the case where a tabular structure does not have the required flexibility, each instance must be described separately.
Spectrum of Information Management Comprehension
editAn automated custodian becomes more capable when it understands more about the content it is managing. The degree of comprehension can be visualized as a spectrum from "black box" to "completely described"
- Black box: the system knows nothing about the contents of the item. The item can be stored and retrieved, but nothing else can be done. This is analogous to throwing all files in a single directory with cryptic names. The only method of searching for content is to perform a full text search for likely keywords.
- Classified black box: the system knows very little about the contents of the item. Predefined groups of items are explicitly constructed. This is analogous to devising a directory structure or filing scheme, into which all items are filed. Full text searches may be combined with group. It is not possible for the system to form new groups which have an unanticipated organizing principle.
- Tagged items: in addition to a predefined filing scheme, a free-text keywording system associates descriptive phrases with information resources.
- Property-value associations: a generalization of "tagging", each item can be associated with a set of properties; each of which has it's own set of values. A property imposes an interpretation on it's value. The text of the "Author" property is expected to be the name of an author. Likewise, properties may have a "type": like a number or a date. Properties help to make searches and filters much more precise and narrow down the results. Properties serve as a summary of the salient characteristics of the managed item. A well-designed set of properties makes it possible to quickly locate information resources which are relevant in a context not anticipated by the Producers.
- References to/associations of managed items: the system provides a way for one item to refer to another in a semantically meaningful way. The reference may be bidirectional or unidirectional, and may have arbitrary multiplicities on each end. Simple links are not considered to fall in this category. Named links, where the name refers to a specific relationship such as "related resources", "children", or "instruments used", are what is described here.
- Types/interfaces/aspects: collections of property-value associations occur in combination to fully describe an aggregate concept. Information resources would be considered to implement the "interface" or possess the "aspect" if they had values for all required properties belonging to the interface or aspect definition. For instance, a temperature range would specify both a minimum and a maximum temperature; and an information resource would be considered to have the "temperature range" interface if it had both the required minimum and maximum temperature properties. Types, interfaces, and aspects could all be used to limit the legitimate targets of references and associations.
- Database/Datastore: the information resource is completely described in a machine-comprehensible framework. Typically, much work has been invested in defining a common data structure and importing data into that structure. Searches and filters can be precise to the point of selecting a portion of data from a particular source. The information itself is represented in a tabular, XML, object oriented, or similar machine-comprehensible model.
Three main theorems present themselves:
- The benefit of an information management system is directly proportional to the level of automated comprehension.
- The level of automated comprehension is directly proportional to the amount of effort invested in furnishing information to the machine.
- Benefit is largely realized by Consumers, but effort is largely expended by Producers. Custodians need only supply an appropriate tool.
Spectrum of Information Management Accessibility
editMostly from Memory (computers), Computer storage and Memory hierarchy. This spectrum traces the proximity of information to the actor which operates on it. In general, latency increases and bandwidth decreases for items listed later.
Accessibility, in this case, is defined in terms of efficiently retrieving and operating on the data. In most cases, processes which are human-bound (e.g., spend the majority of the time waiting on human input, like word processing) will perform acceptably well with any form of online storage. Processes which are IO bound benefit primarily from increasing the bandwidth which can be sustained between the storage device and the processing unit.
- Internal
- CPU Register File
- Hierarchical CPU cache
- Main
- Main Memory (RAM)
- On-line mass storage (Secondary storage)
- Local Mass Storage device
- On site Networked Mass Storage device
- Remote networked mass storage device
- Tertiary (Tertiary storage)
- Tape library with robotic tape loader.
- Human-loaded tape drive
- Off-line bulk storage
- Removable media
Workflows
editUsing information is one of the primary reasons for gathering it in the first place.
- Completely human operated (computer comprehension not required)
- Machine-guided and tracked human processes (computer understands the process, but not the information)
- Human triggered automatic operation, machine tracked (Human understands the process, machine operates on information and logs activity)
- Fully automated process. (computer understands process and information.)
Presentation Breakdown
editIn this section, the plan for presenting the information on this page in an orderly way is outlined. More than one article is likely to be required.
- Article: Introduction
- Article: Spectrum of Information management
- Article: Roles and Interactions
- Article: Collections and classification
- Article: Defining instances of types
- Article: Worked example: SMURFS data mining
- Article: Worked example: SMURFS analysis
- Article: Summary